
Developing high-performance CUDA kernels requires a deep understanding of GPU architecture, efficient memory management, and careful code tuning to fully exploit the hardware. This guide offers a step-by-step approach to writing CUDA kernels that are both correct and highly performant.
CUDA Language Extensions: The Foundation
Before diving into advanced concepts, it is essential to understand the basic C/C++ language extensions that CUDA introduces. These extensions enable parallel programming on GPUs while maintaining a familiar programming model.
Function Type Qualifiers
CUDA extends C/C++ with function type qualifiers that specify where a function executes and how it can be called:
__global__: Functions that run on the GPU and are called from the CPU (host).__device__: Functions that run on the GPU and can only be called from other GPU functions.__host__: Functions that run on the CPU and can only be called from the CPU (this is the default).
// A kernel function (runs on the GPU, called from the CPU)
__global__ void myKernel(float* data) {
// Kernel code here
}
// A device function (runs on the GPU, called from the GPU)
__device__ float computeValue(float input) {
return input * input;
}
// A function that can be compiled for both host and device
__host__ __device__ float sharedFunction(float x) {
return x + 5.0f;
}
Variable Type Qualifiers
CUDA also provides qualifiers to specify the memory location for variables:
__shared__: Declares a variable in shared memory (accessible by all threads in a block).__device__: Declares a variable in global memory (accessible by all threads and the host).__constant__: Declares a variable in constant memory (read-only for all threads).
__device__ float globalVariable; // Accessible by all threads across the grid
__constant__ float constantValue = 3.14f; // Read-only, cached constant data
__shared__ float sharedArray[256]; // Shared within a thread block
Built-in Variables
CUDA provides built-in variables to help threads determine their position:
threadIdx: Thread index within a block (3D vector: x, y, z).blockIdx: Block index within the grid (3D vector).blockDim: Dimensions of each block (3D vector).gridDim: Dimensions of the grid (3D vector).
Kernel Launch Syntax
Kernels are launched using the triple-angle bracket syntax:
myKernel<<<gridDimensions, blockDimensions, sharedMemBytes, stream>>>(arguments);
Where:
gridDimensions: Number of blocks in the grid (can be of typedim3for 2D/3D grids).blockDimensions: Number of threads per block (can be of typedim3).sharedMemBytes: (Optional) Size in bytes of dynamic shared memory.stream: (Optional) CUDA stream for asynchronous execution.
Don’t worry if you find this syntax confusing at first—later sections include visuals and additional context to help you grasp these concepts quickly.
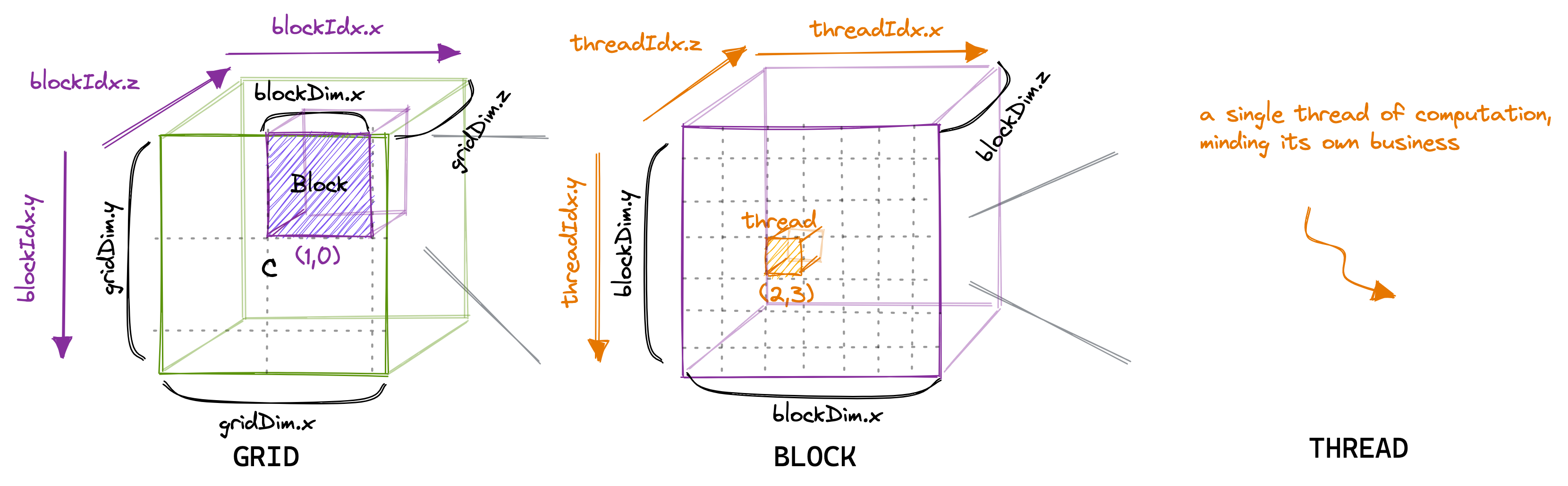
Understanding the CUDA Programming Model
To write effective CUDA kernels, it is important to understand the programming model that underpins the technology. CUDA organizes parallel execution in a hierarchical structure that maximizes both flexibility and performance.

The Thread Hierarchy
When a CUDA kernel is launched, it creates a grid of thread blocks. Each block contains multiple threads that work together closely, sharing resources and synchronizing their execution. This hierarchy naturally decomposes problems into:
- Threads: The basic execution units, each running the same kernel code but processing different data.
- Blocks: Groups of threads that can cooperate using shared memory and synchronization.
- Grids: Collections of blocks that allow the GPU to distribute work across its streaming multiprocessors (SMs).
Each thread has unique coordinates determined by threadIdx, blockIdx, and blockDim, which help in computing the portion of data to process:
// Calculate global thread ID in a 1D grid of 1D blocks
int globalIdx = blockIdx.x * blockDim.x + threadIdx.x;
// Process data corresponding to this thread's position
if (globalIdx < dataSize) {
output[globalIdx] = someOperation(input[globalIdx]);
}
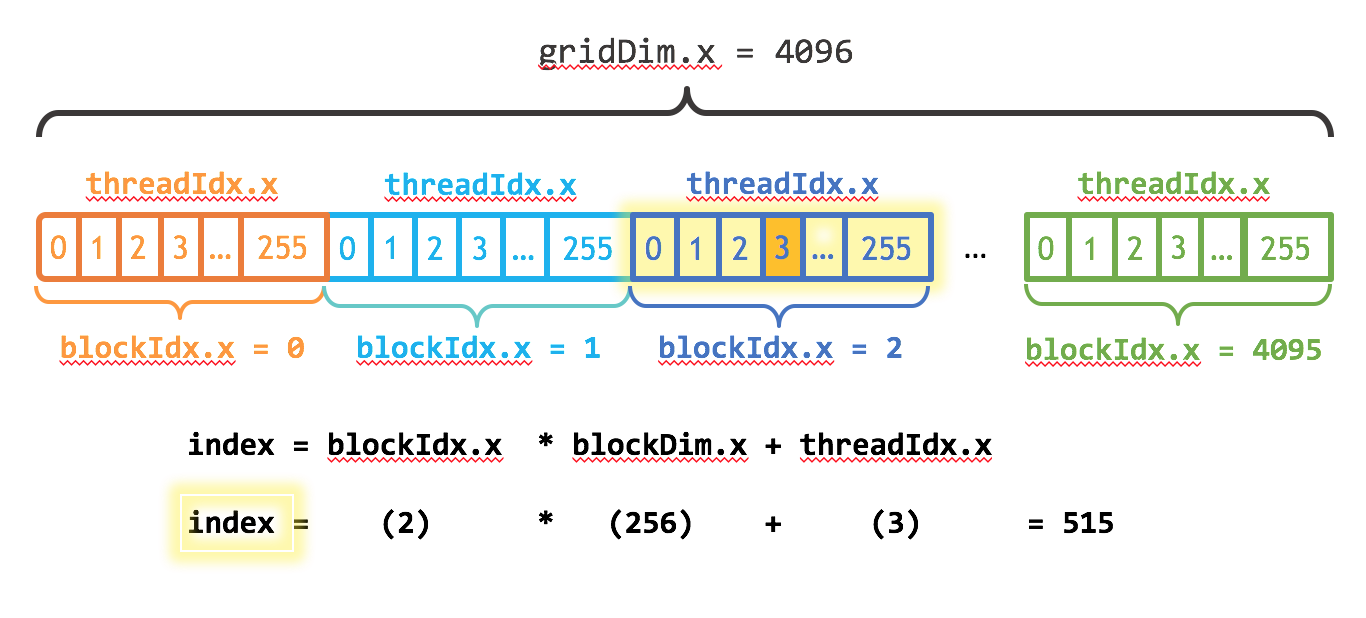
There is a really great article which explains indexing in CUDA. Be sure to check it out if you feel stuck on this part.
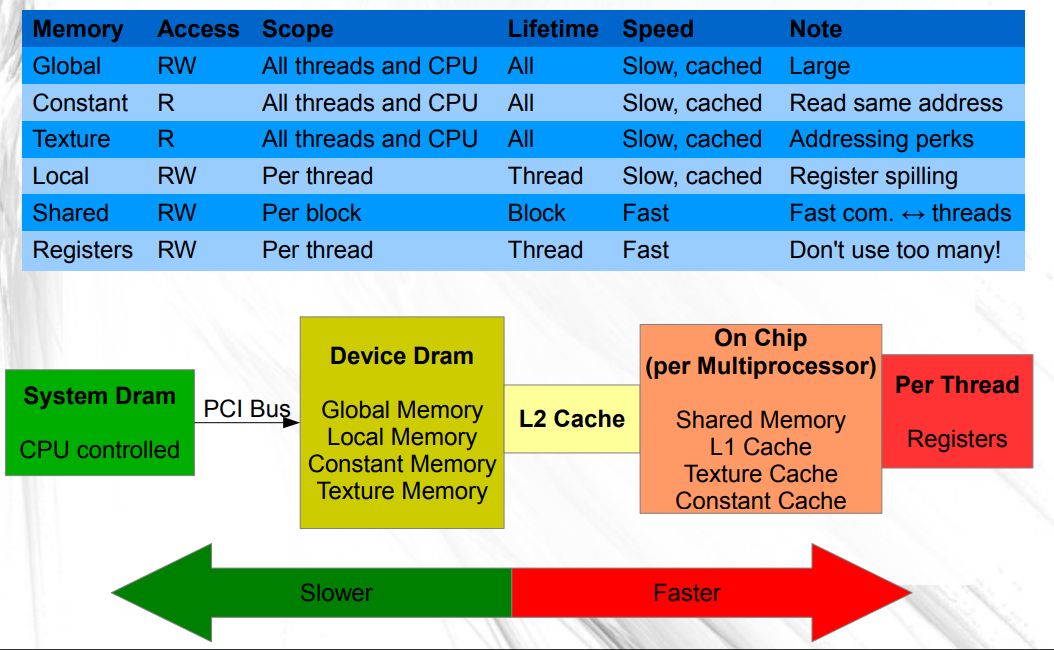
The Memory Hierarchy
CUDA offers various memory types with different performance characteristics:
- Global Memory: Large but with high latency.
- Shared Memory: Fast memory shared among threads in a block.
- Local Memory: Private to each thread, used for register spills.
- Registers: The fastest memory, private to each thread.
- Constant Memory: Read-only memory with a dedicated cache.
- Texture Memory: Optimized for spatial locality with built-in filtering.
Understanding when to use each type is crucial for achieving high performance. For example, copying frequently reused data from global memory to shared memory can significantly reduce access times.
Understanding GPU Hardware Architecture
A solid grasp of the underlying GPU hardware is key to writing effective CUDA code. NVIDIA GPUs are built around a scalable array of Streaming Multiprocessors (SMs), each packed with numerous computing resources.
Streaming Multiprocessors (SMs)
Each SM includes:
- CUDA Cores: For integer and floating-point arithmetic.
- Special Function Units (SFUs): For transcendental functions like sine and cosine.
- Warp Schedulers: Dispatch instructions to execution units.
- Register File: Ultra-fast storage for thread-local variables.
- Shared Memory/L1 Cache: Fast memory shared by threads in a block.
- Tensor Cores (in newer architectures): Specialized units for matrix operations.
When a kernel launches, thread blocks are distributed across available SMs. The resource usage per block (registers, shared memory) directly affects how many blocks can run concurrently.
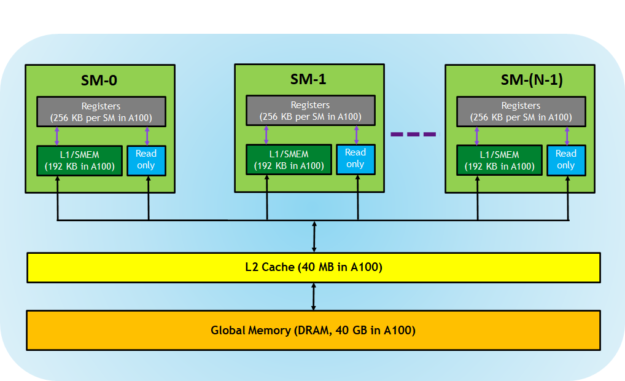
Warp Execution Model
A warp is a group of 32 threads that execute in lockstep—meaning they all execute the same instruction simultaneously, albeit on different data. Each SM contains multiple warp schedulers to manage execution. Note:
- Instructions are issued at the warp level.
- Divergence within a warp (where threads follow different execution paths) can degrade performance because the divergent paths are executed serially.
Memory Hierarchy and Organization
The GPU memory hierarchy is complex and includes several levels:
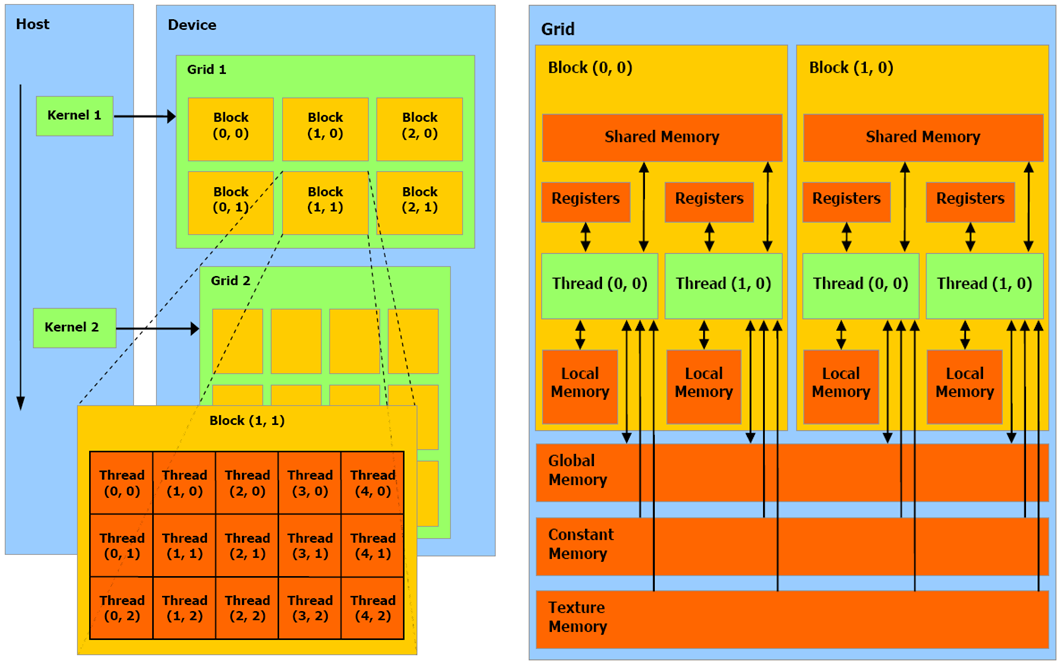
- Global Memory: Highest capacity with high latency; optimized when memory accesses are coalesced.
- L2 Cache: Shared among all SMs to reduce global memory latency.
- Shared Memory: Located on each SM with much lower latency than global memory.
- L1/Texture Cache: Optimized for specific access patterns.
- Registers: The fastest memory, though limited in quantity per thread.
Understanding these elements helps explain why certain optimizations work and informs the design of efficient CUDA code.
Global Memory Access Patterns
Global Memory Organization
Global memory is divided into multiple channels or banks that enable parallel access. Optimizing for coalesced access—where consecutive threads access consecutive memory locations—allows the GPU to combine these accesses into fewer memory transactions, boosting performance.
Memory Coalescing
Memory coalescing minimizes the number of transactions by combining memory accesses from threads in a warp:
// Coalesced access: adjacent threads access adjacent memory
__global__ void coalescedAccess(float* data) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
data[idx] = data[idx] * 2.0f; // Each thread accesses its corresponding element
}
// Non-coalesced access: threads access non-adjacent memory
__global__ void stridedAccess(float* data, int stride) {
int idx = (blockIdx.x * blockDim.x + threadIdx.x) * stride;
data[idx] = data[idx] * 2.0f;
}
Practical Rules for Global Memory Access
For optimal performance:
- Align data structures to appropriate boundaries (typically 128 bytes).
- Ensure the starting address of data is aligned.
- Make adjacent threads access adjacent memory elements.
- Consider using structure-of-arrays instead of an array-of-structures layout.
- Choose appropriate data types (preferably 4, 8, or 16 bytes) for memory transactions.
Writing Your First CUDA Kernel
A simple CUDA kernel typically follows this structure:
__global__ void simpleKernel(float* input, float* output, int size) {
// Calculate global thread ID
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// Check bounds and perform computation
if (idx < size) {
output[idx] = input[idx] * input[idx]; // Square each element
}
}
To launch the kernel from host code:
// Configure kernel launch parameters
int threadsPerBlock = 256;
int blocksPerGrid = (size + threadsPerBlock - 1) / threadsPerBlock;
// Launch the kernel
simpleKernel<<<blocksPerGrid, threadsPerBlock>>>(d_input, d_output, size);
This pattern—calculating a global index, checking bounds, and performing a per-element operation—is the foundation of many CUDA kernels.
Essential Best Practices for CUDA Kernel Development
Adopting best practices can make the difference between an efficient kernel and an underperforming one.
1. Optimize Thread Configuration
Select the number of threads per block as a multiple of 32 (the warp size). Common choices are 128, 256, or 512 threads per block. Use ceiling division to ensure all elements are processed:
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
2. Maximize Occupancy
Occupancy is the ratio of active warps to the maximum possible warps on an SM. Higher occupancy can better hide memory latency. Key factors include:
- Register usage per thread
- Shared memory usage per block
- Block size
Tools like NVIDIA’s Occupancy Calculator or the cudaOccupancyMaxPotentialBlockSize() API can help determine optimal configurations.
3. Coalesce Global Memory Access
Ensure that threads in a warp access consecutive memory locations to allow the GPU to combine these accesses into fewer transactions, improving memory throughput.
4. Utilize Shared Memory Effectively
Shared memory is a programmer-managed cache that can dramatically reduce global memory accesses. Consider the following example of summing neighboring elements:
Without shared memory:
__global__ void sumNeighborsSimple(float* input, float* output, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
float left = (idx > 0) ? input[idx - 1] : 0;
float center = input[idx];
float right = (idx < size - 1) ? input[idx + 1] : 0;
output[idx] = left + center + right;
}
}
Improved with shared memory:
__global__ void sumNeighborsShared(float* input, float* output, int size) {
__shared__ float sharedData[BLOCK_SIZE + 2]; // Block size plus halo elements
int blockStartIdx = blockIdx.x * blockDim.x;
int tid = threadIdx.x;
int globalIdx = blockStartIdx + tid;
// Load main data into shared memory
if (globalIdx < size) {
sharedData[tid + 1] = input[globalIdx];
}
// Load halo elements at block boundaries
if (tid == 0) {
sharedData[0] = (blockStartIdx > 0) ? input[blockStartIdx - 1] : 0;
}
if (tid == blockDim.x - 1 || globalIdx == size - 1) {
sharedData[tid + 2] = (globalIdx < size - 1) ? input[globalIdx + 1] : 0;
}
__syncthreads();
// Compute the sum using shared memory
if (globalIdx < size) {
output[globalIdx] = sharedData[tid] + sharedData[tid + 1] + sharedData[tid + 2];
}
}
5. Minimize Divergent Execution
Avoid conditional branches that cause threads within the same warp to follow different execution paths. For example:
// Causes divergence: alternate threads take different branches
if (threadIdx.x % 2 == 0) {
// Even threads
} else {
// Odd threads
}
// Better: using a condition common to all threads in the block
if (blockIdx.x % 2 == 0) {
// All threads follow the same branch
}
6. Avoid Shared Memory Bank Conflicts
Shared memory is divided into banks (typically 32 on modern GPUs). When multiple threads access different addresses within the same bank simultaneously, accesses are serialized. To prevent this, consider adding padding to your shared memory arrays:
// Potential conflict: threads may access the same bank
__shared__ float data[256];
float value = data[threadIdx.x * 32];
// Conflict-free: with padding to shift bank assignments
__shared__ float dataPadded[256 + 1];
float valuePadded = dataPadded[threadIdx.x * 32];
7. Use Appropriate Data Types
Selecting the right data types can improve both computation and memory performance:
- Use 32-bit types (float, int) when possible.
- Consider vectorized types (e.g.,
float4,int4) for increased bandwidth. - Use lower-precision types (e.g., half, char) if accuracy permits.
Example of vectorized memory access:
// Scalar version
for (int i = 0; i < N; i++) {
output[i] = input[i] * scalar;
}
// Vectorized version (4x fewer memory operations)
for (int i = 0; i < N / 4; i++) {
float4 in = reinterpret_cast<float4*>(input)[i];
in.x *= scalar;
in.y *= scalar;
in.z *= scalar;
in.w *= scalar;
reinterpret_cast<float4*>(output)[i] = in;
}
8. Leverage Compiler Optimizations
CUDA’s compiler (NVCC) offers flags and attributes that can boost performance.
Basic Compiler Flags:
-O3 // Highest level of optimization
--use_fast_math // Use fast (but less accurate) math functions
-Xptxas=-v // Display register/memory usage statistics
-maxrregcount=N // Limit register usage per thread
Function Attributes:
// Inform the compiler about resource usage
__global__ void __launch_bounds__(256, 2) myKernel() {
// Maximum 256 threads per block, with at least 2 blocks per SM
}
Loop Unrolling:
#pragma unroll 4
for (int i = 0; i < 16; i++) {
result += data[i];
}
Explicit Inlining:
__device__ __forceinline__ float square(float x) {
return x * x;
}
Memory Alignment:
struct __align__(16) AlignedStruct {
float4 data;
int count;
};
Advanced CUDA Optimization Techniques
Once you master the basics, the following advanced techniques can further improve kernel performance.
Dynamic Parallelism
Dynamic parallelism (introduced in compute capability 3.5) lets kernels launch child kernels, enabling nested parallelism:
__global__ void parentKernel() {
if (someCondition()) {
// Launch a child kernel
childKernel<<<blocks, threads>>>();
}
}
Warp-Level Primitives
For devices with compute capability 3.0 and above, warp-level primitives offer efficient synchronization and communication:
// Warp-level reduction using shuffle
__device__ float warpReduceSum(float val) {
for (int offset = warpSize / 2; offset > 0; offset /= 2) {
val += __shfl_down_sync(0xffffffff, val, offset);
}
return val;
}
// Block-wide reduction using warp-level primitives
__device__ float blockReduceSum(float val) {
static __shared__ float shared[32]; // One partial sum per warp
int lane = threadIdx.x % warpSize;
int wid = threadIdx.x / warpSize;
// Each warp performs a reduction
val = warpReduceSum(val);
// Write reduced value to shared memory
if (lane == 0) shared[wid] = val;
__syncthreads();
// Final reduction performed by the first warp
val = (threadIdx.x < blockDim.x / warpSize) ? shared[lane] : 0;
if (wid == 0) val = warpReduceSum(val);
return val;
}
Cooperative Groups
Introduced in CUDA 9, Cooperative Groups provide fine-grained control over thread synchronization:
#include <cooperative_groups.h>
namespace cg = cooperative_groups;
__global__ void cooperativeKernel(float* data) {
cg::thread_block block = cg::this_thread_block();
block.sync();
cg::thread_block_tile<32> tile32 = cg::tiled_partition<32>(block);
tile32.sync();
cg::grid_group grid = cg::this_grid();
grid.sync();
}
Tensor Cores
For matrix-intensive applications, Tensor Cores (available in newer GPUs) significantly accelerate matrix multiply-accumulate operations, especially with half-precision inputs:
#include <mma.h>
using namespace nvcuda::wmma;
__global__ void tensorCoreMatrixMultiply(half* A, half* B, float* C, int M, int N, int K) {
// Declare fragments
fragment<matrix_a, 16, 16, 16, half, row_major> a_frag;
fragment<matrix_b, 16, 16, 16, half, col_major> b_frag;
fragment<accumulator, 16, 16, 16, float> c_frag;
fill_fragment(c_frag, 0.0f);
load_matrix_sync(a_frag, A, K);
load_matrix_sync(b_frag, B, K);
mma_sync(c_frag, a_frag, b_frag, c_frag);
store_matrix_sync(C, c_frag, N, mem_row_major);
}
Debugging and Profiling CUDA Kernels
Effective debugging and profiling are key to developing robust and optimized CUDA kernels.
Error Checking
Always check CUDA API calls for errors:
#define CHECK_CUDA_ERROR(call) \
do { \
cudaError_t error = call; \
if (error != cudaSuccess) { \
fprintf(stderr, "CUDA error: %s at %s:%d\n", \
cudaGetErrorString(error), __FILE__, __LINE__); \
exit(EXIT_FAILURE); \
} \
} while(0)
// Example usage:
CHECK_CUDA_ERROR(cudaMalloc(&d_data, size));
Also, check kernel launches:
myKernel<<<blocks, threads>>>(args);
CHECK_CUDA_ERROR(cudaGetLastError());
CHECK_CUDA_ERROR(cudaDeviceSynchronize());
CUDA-GDB and cuda-memcheck
- cuda-gdb: Source-level debugging of device code.
- cuda-memcheck: Detects memory errors like out-of-bounds accesses.
NVIDIA Nsight and Visual Profiler
Tools such as NVIDIA Nsight Systems, Nsight Compute, and Visual Profiler help identify performance bottlenecks by providing metrics on memory throughput, compute utilization, warp efficiency, and instruction throughput.
Common CUDA Kernel Optimization Patterns
Recognizing common optimization patterns can save development time.
Tiling Pattern
Dividing input data into tiles that fit in shared memory minimizes global memory accesses:
__global__ void matrixMultiplyTiled(float* A, float* B, float* C, int M, int N, int K) {
__shared__ float As[TILE_SIZE][TILE_SIZE];
__shared__ float Bs[TILE_SIZE][TILE_SIZE];
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
float sum = 0.0f;
for (int t = 0; t < (K + TILE_SIZE - 1) / TILE_SIZE; t++) {
if (row < M && t * TILE_SIZE + threadIdx.x < K) {
As[threadIdx.y][threadIdx.x] = A[row * K + t * TILE_SIZE + threadIdx.x];
} else {
As[threadIdx.y][threadIdx.x] = 0.0f;
}
if (col < N && t * TILE_SIZE + threadIdx.y < K) {
Bs[threadIdx.y][threadIdx.x] = B[(t * TILE_SIZE + threadIdx.y) * N + col];
} else {
Bs[threadIdx.y][threadIdx.x] = 0.0f;
}
__syncthreads();
for (int i = 0; i < TILE_SIZE; i++) {
sum += As[threadIdx.y][i] * Bs[i][threadIdx.x];
}
__syncthreads();
}
if (row < M && col < N) {
C[row * N + col] = sum;
}
}
Thread Coarsening
Thread coarsening lets each thread process multiple elements, reducing overhead and increasing instruction-level parallelism:
__global__ void vectorAddCoarsened(float* A, float* B, float* C, int N) {
int i = blockIdx.x * blockDim.x * 4 + threadIdx.x;
if (i + 3 * blockDim.x < N) {
float a1 = A[i];
float a2 = A[i + blockDim.x];
float a3 = A[i + 2 * blockDim.x];
float a4 = A[i + 3 * blockDim.x];
float b1 = B[i];
float b2 = B[i + blockDim.x];
float b3 = B[i + 2 * blockDim.x];
float b4 = B[i + 3 * blockDim.x];
C[i] = a1 + b1;
C[i + blockDim.x] = a2 + b2;
C[i + 2 * blockDim.x] = a3 + b3;
C[i + 3 * blockDim.x] = a4 + b4;
} else {
// Handle the boundary case for remaining elements
for (int j = 0; j < 4; j++) {
int idx = i + j * blockDim.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
}
}
Persistent Threads
The persistent threads pattern keeps GPU threads active over the lifetime of the application, dynamically fetching work to improve load balancing:
__global__ void persistentKernel(volatile int* queue, volatile int* queueCounter,
float* data, int maxItems) {
while (true) {
int itemIdx = -1;
if (threadIdx.x == 0) {
itemIdx = atomicAdd((int*)queueCounter, 1);
}
// Broadcast the work index to all threads in the block
itemIdx = __shfl_sync(0xffffffff, itemIdx, 0);
if (itemIdx >= maxItems) {
break; // Exit if no more work
}
// Process the work item
processItem(data, itemIdx);
}
}
CUDA Kernel Best Practices Checklist
Use the following checklist to ensure your kernels adhere to best practices:
- Memory Access Patterns
- Ensure global memory accesses are coalesced.
- Use shared memory for frequently reused data.
- Avoid bank conflicts in shared memory.
- Consider texture memory for read-only data with spatial locality.
- Thread Organization
- Choose thread block sizes that are multiples of 32 (warp size).
- Balance resource usage (registers, shared memory) to maximize occupancy.
- Minimize divergent execution within warps.
- Apply thread coarsening in compute-bound kernels.
- Synchronization and Communication
- Limit thread synchronization.
- Use warp-level primitives when possible.
- Leverage cooperative groups for flexible synchronization.
- Employ effective reduction patterns.
- Resource Usage
- Monitor register and shared memory usage.
- Use compiler hints like
__launch_bounds__appropriately.
- Error Handling
- Check CUDA API calls and kernel launches for errors.
- Use tools like
cuda-memcheckfor detecting memory errors.
- Performance Analysis
- Profile kernels to identify bottlenecks.
- Compare achieved performance against theoretical limits.
- Explore alternative algorithms if necessary.
Conclusion
CUDA kernel development merges the challenges of parallel programming with the nuances of GPU architecture. By mastering the fundamentals and applying the best practices outlined in this guide, you can harness the full computational power of modern GPUs.
Remember, optimization is an iterative process. Start with a correct implementation, profile to identify bottlenecks, and then methodically apply optimizations. Often, the most significant improvements come from algorithmic changes rather than low-level tweaks.
As GPU hardware continues to evolve, so too will the best practices for CUDA kernel development. Stay informed about new CUDA features and adapt your techniques accordingly.
Embracing the Learning Journey
It’s important to note that the domain of CUDA programming is vast and continually evolving. Many developers find that mastering CUDA involves a lot of trial and error, reading blogs and articles, and examining others’ code. If you didn’t fully grasp every detail in this guide, know that this is a normal part of learning a complex technology. Every individual’s path to understanding CUDA can be different—what matters is persistence, continuous learning, and practical experience. Embrace the challenges and enjoy the process of discovery as you refine your skills.
Happy coding, and may your kernels run efficiently!